



- At Open Compute Project Summit (OCP) 2024, we’re sharing details about our next-generation network fabric for our AI training clusters.
- We’ve expanded our network hardware portfolio and are contributing two new disaggregated network fabrics and a new NIC to OCP.
- We look forward to continued collaboration with OCP to open designs for racks, servers, storage boxes, and motherboards to benefit companies of all sizes across the industry.
At Meta, we believe that open hardware drives innovation. In today’s world, where more and more data center infrastructure is being devoted to supporting new and emerging AI technologies, open hardware takes on an important role in assisting with disaggregation. By breaking down traditional data center technologies into their core components we can build new systems that are more flexible, scalable, and efficient.
Since helping found OCP in 2011, we’ve shared our data center and component designs, and open-sourced our network orchestration software to spark new ideas both in our own data centers and across the industry. Those ideas have made Meta’s data centers among the most sustainable and efficient in the world. Now, through OCP, we’re bringing new open advanced network technologies to our data centers, and the wider industry, for advanced AI applications.
We’re announcing two new milestones for our data centers: Our next-generation network fabric for AI, and a new portfolio of network hardware that we’ve developed in close partnership with multiple vendors.

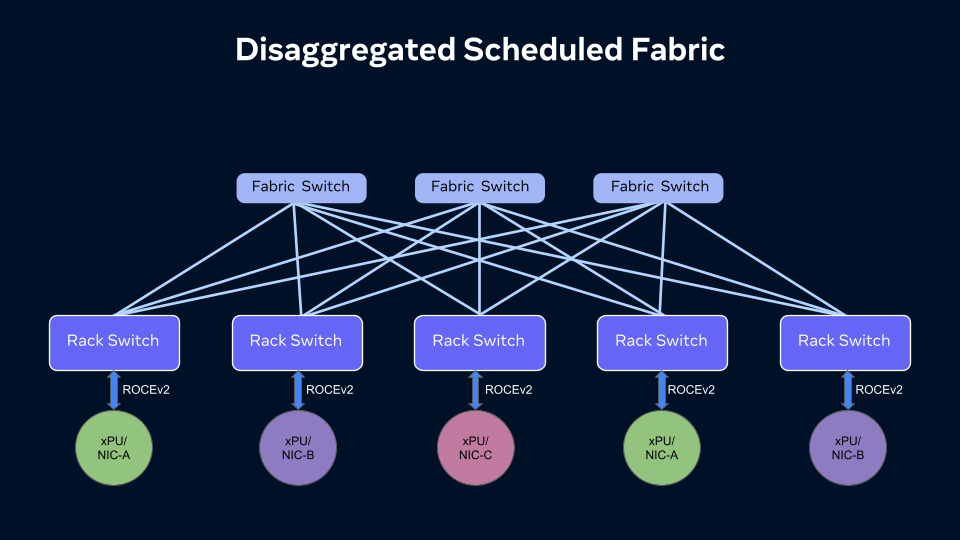
DSF: Scheduled fabric that is disaggregated and open
Network performance and availability play an important role in extracting the best performance out of our AI training clusters. It’s for that reason that we’ve continued to push for disaggregation in the backend network fabrics for our AI clusters. Over the past year we have developed a Disaggregated Scheduled Fabric (DSF) for our next-generation AI clusters to help us develop open, vendor-agnostic systems with interchangeable building blocks from vendors across the industry. DSF-based fabrics allow us to build large, non-blocking fabrics to support high-bandwidth AI clusters.
DSF extends our disaggregating network systems to our VoQ-based switched systems that are powered by the open OCP-SAI standard and FBOSS, Meta’s own network operating system for controlling network switches. VoQ-based traffic scheduling ensures proactive congestion avoidance in the fabric rather than reactive congestion signaling and reaction.
The DSF fabric supports an open and standard Ethernet-based RoCE interface to endpoints and accelerators across several xPUs and NICs, including Meta’s MTIA as well as from several vendors.
DSF platforms for next-generation AI fabrics
Arista 7700R4 series
The DSF platforms, Arista 7700R4 series, consist of dedicated leaf and spine systems that are combined to create a large, distributed switch. As a distributed system, DSF is designed to support high scale AI clusters.


7700R4C-38PE: DSF Leaf Switch
- DSF Distributed Leaf Switch (Broadcom Jericho3-AI based)
- 18 x 800GE (36 x 400GE) OSFP800 host ports
- 20 x 800Gbps (40 x 400Gbps) fabric ports
- 14.4Tbps of wirespeed performance with 16GB of buffers


7720R4-128PE: DSF Spine Switch
- DSF Distributed Spine Switch (Broadcom Ramon3 based)
- Accelerated compute optimized pipeline
- 128 x 800Gbps (256 x 400Gbps) fabric ports
- 102.4Tbps of wirespeed performance
51T switches for next-generation 400G/800G fabrics


Meta will deploy two next-generation 400G fabric switches, the Minipack3 (the latest version of Minipack, Meta’s own fabric network switch) and the Cisco 8501, both of which are also backward compatible with previous 200G and 400G switches and will support upgrades to 400G and 800G.
The Minipack3 utilizes Broadcom’s latest Tomahawk5 ASIC while the Cisco 8501 is based on Cisco’s Silicon One G200 ASIC. These high-performance switches transmit up to 51.2 Tbps with 64x OSFP ports, and the design is optimized without the need of retimers to achieve maximum power efficiency. They also have significantly reduced power per bit compared with predecessor models.
Meta will run both the Minipack3 and Cisco 8501 on FBOSS.


Optics: 2x400G FR4 optics for 400G/800G optical interconnection


Meta’s data center fabrics have evolved from 200 Gbps/400 Gbps to 400 Gbps/800 Gbps and we’ve already deployed 2x400G optics in our data centers.
Evolving FBOSS and SAI for DSF
![]()

We continue to embrace OCP-SAI to onboard the new network fabrics, switch hardware platforms, and optical transceivers to FBOSS. We have collaborated with vendors, and the OCP community, to evolve SAI. It now supports new features and concepts like DSF and other enhanced routing schemes.
Developers and engineers from all over the world can work with this open hardware and contribute their own software that they, in turn, can use themselves and share with the wider industry.
FBNIC: A multi-host foundational NIC designed by Meta


We are continuing to design more ASICs, including the ASIC for FBNIC. FBNIC is a true multi-host foundational NIC and contains the first of our Meta-designed network ASICs for our server fleet and MTIA solutions. It can support up to four hosts with complete datapath isolation for each host.The FBNIC driver has been upstreamed (available from v6.11 kernel). The NIC module was designed by Marvell and has been contributed to OCP.
FBNIC’s key features include:
- Network interfaces for up to 4×100/4×50/4×25 GE with SerDes support for up to 56G PAM4 per lane.
- Up to 4 independent PCIe Gen5 slices
- HW offloads including LSO, Checksum
- Line rate timestamping (for each host all the way from PHY) for PTP
- Header-Data split to assist Zero-Copy
- Compliant with OCP NIC 3.0, version 1.2.0, design specification
The future is open
Advancing AI means building data center infrastructure that goes beyond scale. It also has to allow for flexibility and perform efficiently and sustainably. At Meta, we envision a future of AI hardware systems that are not only scalable, but also open and collaborative.
We encourage anyone who wants to help advance the future of networking hardware for AI to engage with OCP and Meta to help share the future of AI infrastructure.
link